Building digital twins of articulated objects from monocular video presents an essential challenge in computer vision, which requires simultaneous reconstruction of object geometry, part segmentation, and articulation parameters from limited viewpoint inputs. Monocular video offers an attractive input format due to its simplicity and scalability; however, it's challenging to disentangle the object geometry and part dynamics with visual supervision alone, as the joint movement of the camera and parts leads to ill-posed estimation. While motion priors from pre-trained tracking models can alleviate the issue, how to effectively integrate them for articulation learning remains largely unexplored.
To address this problem, we introduce VideoArtGS, a novel approach that reconstructs high-fidelity digital twins of articulated objects from monocular video. We propose a motion prior guidance pipeline that analyzes 3D tracks, filters noise, and provides reliable initialization of articulation parameters. We also design a hybrid center-grid part assignment module for articulation-based deformation fields that captures accurate part motion.
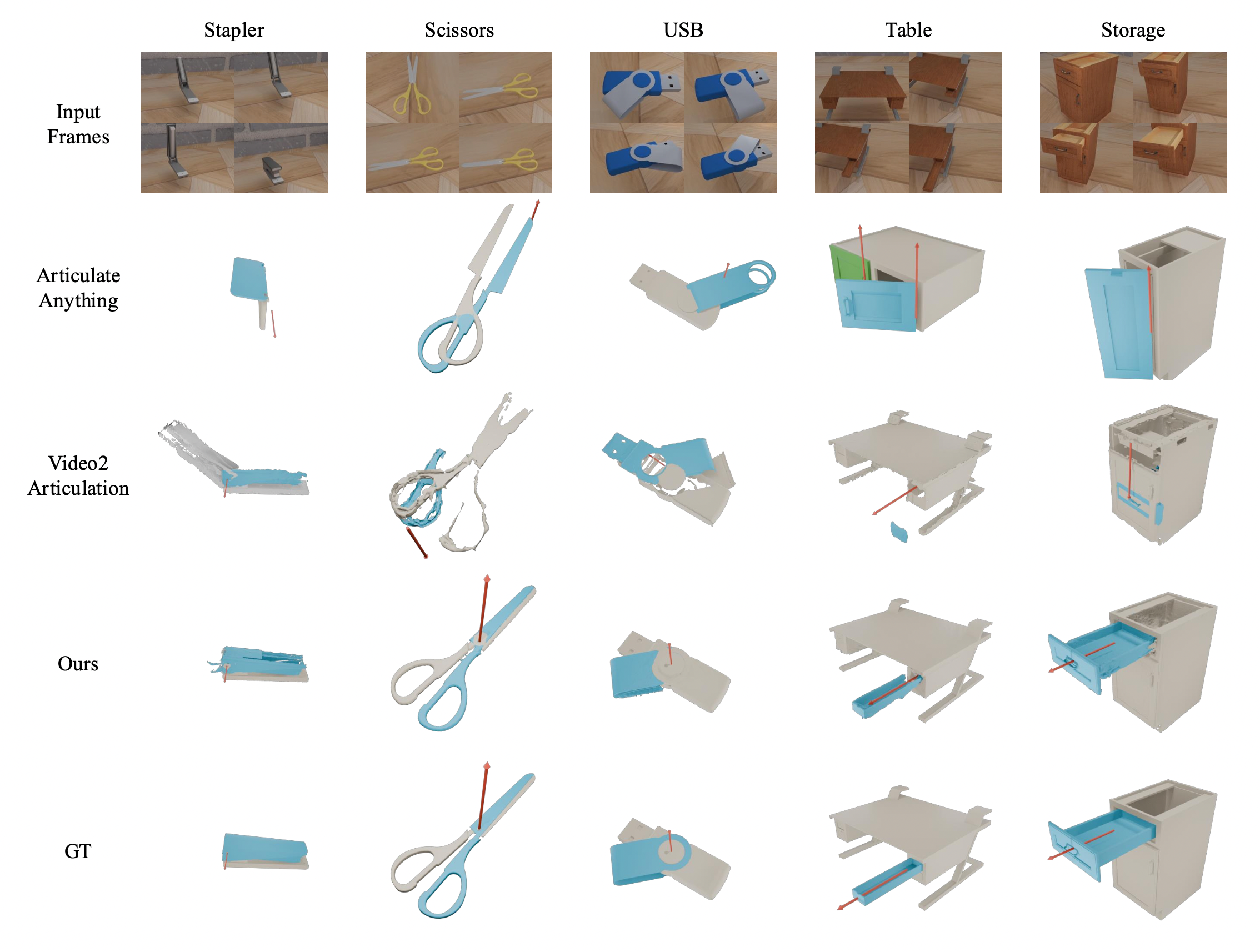
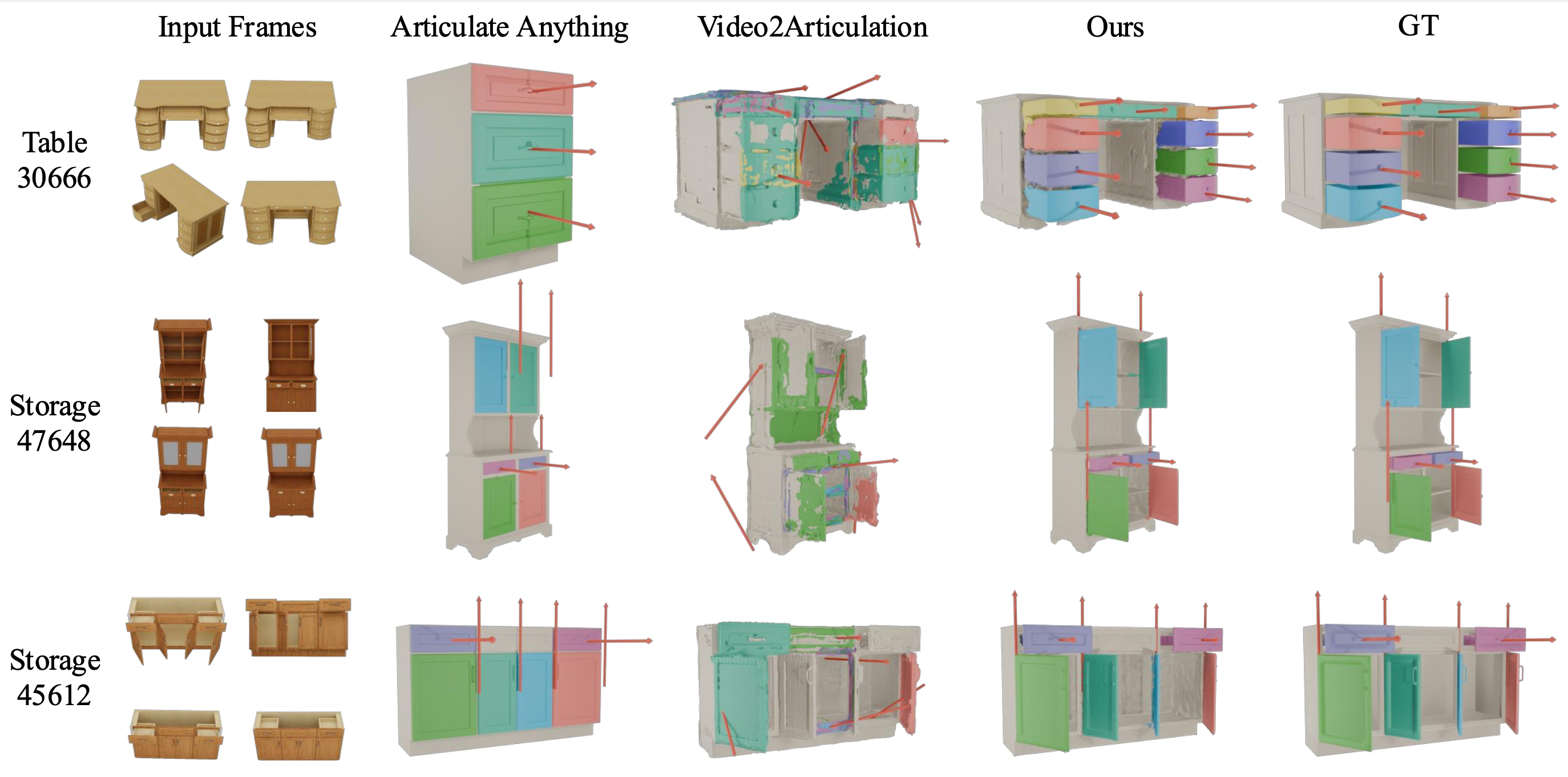
VideoArtGS demonstrates state-of-the-art performance in articulation and mesh reconstruction, reducing the reconstruction error by about two orders of magnitude compared to existing methods. VideoArtGS enables practical digital twin creation from monocular video, establishing a new benchmark for video-based articulated object reconstruction.